Come funziona Internet
Il funzionamento della Rete in breve
DNS
Quando andiamo sul sito www.google.com per cercare qualcosa, come fa il nostro dispositivo a saper dove andare a cercare?
Ogni dispositivo che può collegarsi ad Internet ha un indirizzo IP che lo rende unico ed identificabile tramite questo.
Un indirizzo IP può essere composto da soli numeri (IPv4, come 127.0.0.1) oppure da numeri e lettere (IPv6, come 2001:db8::ff00:42:8329).
Ricordarsi i vari IP che ci interessano sarebbe piuttosto scomodo, quindi viene usato il Domain Name System (DNS).
Il server DNS funziona un po' come le pagine gialle: vi è un elenco di indirizzi IP a cui sono collegati i nomi di dominio.
Il nostro client chiede al server DNS di risolvere il dominio Google.com, restituendo l'indirizzo IP.
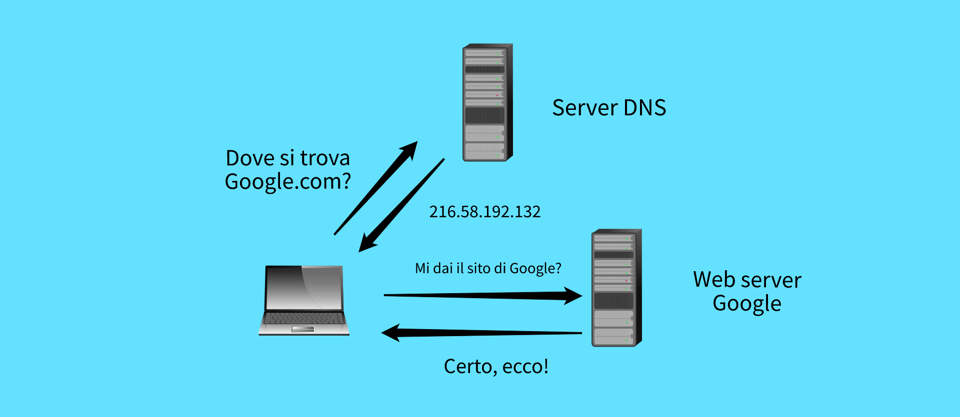
Dopo che il client ha ottenuto l'indirizzo IP a cui collegarsi, lo farà tramite una porta.
Una porta è costrutto logico sui dispositivi che identifica uno specifico servizio di rete.
Le porte vengono distinti in numeri, e vanno da 0 a 65535.
Le porte permettono ad un dispositivo (come ad un server) di fornire più servizi contemporaneamente.
Di solito le porte identificano anche un servizio utilizzato, perché si è soliti assegnare alcuni servizi a porte specifiche: 21 per FTP, 80 per HTTP, 443 per HTTPS, 22 per SSH, 23 per Telnet e così via.
Porte Logiche
Richieste e risposte HTTP
Una volta che il client forma una connessione con il server, questi comunicano attraverso il protocollo HTTP (HyperText Transfer Protocol).
Questo protocollo è un insieme di regole che specificano come strutturare e interpretare i messaggi internet e come avviene uno scambio d'informazioni.
Quando un client vuole comunicare con un server, manda una richiesta HTTP.
Ci sono diversi tipi di richieste HTTP, e le più comuni sono GET e POST.
La prima viene usata per leggere dati da un server, mentre la seconda di inserirvi dati (come scrivere un messaggio su un forum).
Altri metodi sono PUT e DELETE, per aggiornare una risorsa e per cancellarla rispettivamente.
Ecco un esempio di una richiesta GET che chiede al server di mostrare www.google.com:
GET / HTTP/1.1
Host: www.google.com
User-Agent: Mozilla/5.0
Accept: text/html,application/xhtml+xml,application/xml
Accept-Language: en-US
Accept-Encoding: gzip, deflate
Connection: close
Ora esaminiamo la struttura di questa richiesta.
La prima riga specifica il metodo di richiesta, l'URL richiesto, e la versione del protocollo HTTP usata.
Le altre righe vengono definite gli header della richiesta, e vengono usate per aggiungere altre informazioni sulla richiesta al server. Questo permette al server di personalizzare la risposta.
Host identifica l'hostname della richiesta.
User-Agent contiene il sistema operativo e la versione del software da cui parte la richiesta (il browser).
Accept, Accept-Language e Accept-Encoding specificano al server il tipo di formato per la risposta.
Vi possono essere altri tipi di header, alcuni esempi sono il Referer e l'Authorization, usati per indicare il sito della pagina precedente che ci ha portato a questa pagina e per verificare che un utente abbia il permesso di accedere a specifiche risorse.
A questo punto il server cercherà di costruire una risposta HTTP.
La risposta HTTP è divisa in tre punti: un codice di risposta per indicare se la richiesta ha avuto successo o meno, vari header HTTP, informazioni usate per poter far comunicare client e server e che specificano alcune cose come autenticazione, formattazione del contenuto e il corpo di risposta HTTP, ciò che è stato effettivamente richiesto.
Ecco un esempio di una risposta HTTP:
HTTP/1.1 200 OK
Date: Thu, 12 Jan 2023 12:02:03 GMT
[...]
Content-Type: text/html; charset=UTF-8
Server: gws
Content-Lenght: 202222
<!doctype html>
...
Nella prima linea possiamo leggere il codice di status: 200 indica che la richiesta è stata completata con successo.
Vengono usati diversi range per esprimere diversi tipi di risultati: il range 300 indica il reindirizzamento, il range 400 indica un errore da parte del client e il range 500 indica un errore da parte del server.
Le linee separate da i due punti (:) sono gli header della risposta e permettono al server di fornire informazioni aggiuntive sulla risposta, come la data, il tipo di file nel corpo di risposta (in questo caso text/html), la versione del server e la lunghezza del contenuto.
Tutto il resto è il corpo della risposta, ed è la pagina che è stata richiesta in formato html (la linea <!doctype html> serve a questo).
Gestione della sessione e autenticazione
Perché, dopo che ti logghi in un sito, non hai più bisogno di farlo? Perché il sito si ricorda di te. Il session management è un processo che permette al server di gestire più richieste dallo stesso utente, senza chiedergli di riloggare.
Quando ci si logga in un sito, il server assegna un ID di sessione al tuo browser.
Questo ID è di solito lungo e composto da una sequenza che non dovrebbe essere indovinabile. Quando ci si slogga, il server chiude la sessione e revoca l'ID.

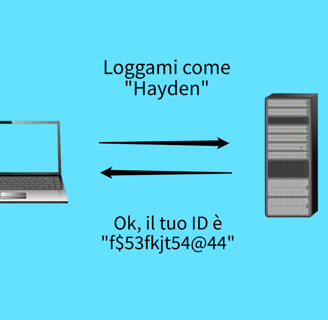
La maggior parte dei siti web usano i cookie per comunicare le informazioni di sessioni nelle richieste HTTP. Questo cookie sono piccole informazioni che i server web mandano al browser. Quando ci si logga in un sito, il server crea una sessione e manda l'ID di questa al tuo browser sotto forma di cookie.
Dopo averlo ricevuto, il browser lo salva e lo include in ogni richiesta che farà allo stesso server.
Ecco come ti riconosce! Dopo che il cookie viene creato, il server ne terrà traccia e lo userà per autenticarti. Quando slogghi, il server renderà nullo questo cookie in modo che non possa più essere usato.
La prossima volta che logghi, il server creerà una nuova sessione e quindi un nuovo cookie.
Autenticazione con Token
Nell'autenticazione a sessione, il server salva le tue informazioni e usa un'id di sessione per verificare la tua identità, mentre nell'autenticazione con token il sistema salva quest'informazione in un token.
Invece di salvare le tue informazioni lato server e andarle a riprendere tramite un ID, i token permettono ai server di capire la tua identità decodificando il token. In questo modo le applicazioni non devono salvare le informazioni di sessione lato server.
Questo sistema ha però un problema, qualcuno nno potrebbe semplicemente modificare questo token contenuto lato client?.
Per prevenire attacchi di token forgeri, alcune applicazioni criptano i loro token, o li codificano in modo che possano essere letti solo dall'applicazione stessa o da altri autorizzati. Se l'utente non capisce il contenuto del token, probabilmente non lo possono modificare.
Tuttavia, codificare o criptare i token non è una soluzione totalmente efficace.
Ci sono modi per modificare un token criptato senza capirne il contenuto.
Un altro modo per proteggere l'integrità del token è di firmarlo e verificare la firma del token quando arriva al server.
Le firme vengono usate per verificare l'integrità di un qualche dato. Sono stringhe speciali che possono essere generate solo se si conosce una chiave segreta. Siccome non c'è nessun modo di geneerare una firma valida senza la chiave segreta, e solo il server la conosce, una firma valida suggerisce che il token non è stato probabilmente modificato. Generalmente, il procedimento è il seguente:
1. L'utente logga.
2. Il server verifica le credenziali e fornisce all'utente un token firmato.
3. L'utente manda il token con ogni richiesta.
4. Dopo aver verificato il token, il server legge le informazioni sull'identità dell'utente dal token e risponde con i dati richiesti.